
A Comprehensive Guide to Text Prompt Engineering Techniques
My Summary and Notes from all Text-Based Prompting Techniques in "The Prompt Report" Paper and many of its cited works


I read "The Prompt Report: A Systematic Survey of Prompting Techniques" from start to finish, as well as many of the papers it cited and extracted all the things that I thought were useful techniques to have in the text-prompting toolbelt (left out all the benchmarking and multi-modal techniques).
Here's everything; maybe you'll find it useful too:
1. In-Context Learning (ICL) and Few-Shot Prompting
In-Context Learning (ICL) is a type of few-shot prompting technique. It allows AI models to perform tasks based on a small number of examples or instructions within the prompt, without additional training.
1.1 Key Concepts of ICL
Skills can be derived from exemplars or instructions in the prompt
May utilize pre-existing knowledge rather than true "learning"
Viewed as task specification rather than acquiring new skills
Current research focuses on optimization and understanding of ICL
1.2 Examples of ICL
Learning from exemplars:
System:
Translate English to French:
English: Hello
French: Bonjour
English: Goodbye
French: Au revoir
---
User:
English: How are you?Learning from instructions:
System Prompt:
Identify the subject and predicate in sentences. The subject is the doer, and the predicate is the action.
Example:
Sentence: The cat chased the mouse.
Subject: The cat
Predicate: chased the mouse
Now, your turn:
--
User:
Sentence: The sun rises in the east.
[Model identifies subject and predicate]Task specification:
Prompt:
Generate a haiku about artificial intelligence. A haiku is a three-line poem with five syllables in the first line, seven in the second, and five in the third.ICL enables flexible task performance without fine-tuning, but its effectiveness depends on prompt design and example selection. The technique is limited by the model's maximum input length and may not represent true learning of new skills.
1.3 Few-Shot Prompting Design Decisions
The effectiveness of ICL and few-shot prompting techniques depends significantly on how the examples (exemplars) are designed and presented. Here are six critical design decisions:
1.3.1 Exemplar Quantity
Generally, more exemplars improve performance, especially in larger models.
Benefits may diminish beyond 20 exemplars in some cases.
1.3.2 Exemplar Ordering
The order of exemplars affects model behavior.
On some tasks, exemplar order can cause accuracy to vary from below 50% to over 90%.
1.3.3 Exemplar Label Distribution
The distribution of labels in exemplars can bias the model's output.
Example: 10 exemplars of one class and 2 of another may bias the model towards the first class.
1.3.4 Exemplar Label Quality
The necessity of strictly valid demonstrations is unclear.
Some studies suggest label accuracy may be irrelevant, while others show significant impact.
Larger models often handle incorrect or unrelated labels better.
Note: When automatically constructing prompts from large datasets, consider studying how label quality affects your results.
1.3.5 Exemplar Format
Common format: "Q: {input}, A: {label}"
Optimal format may vary across tasks; experiment with multiple formats.
Formats common in the training data may lead to better performance.
1.3.6 Exemplar Similarity
Selecting exemplars similar to the test sample is generally beneficial.
In some cases, more diverse exemplars can improve performance.
These design decisions critically influence output quality in few-shot prompting and ICL.
2. Few-Shot Prompting Techniques
Few-Shot Prompting can be challenging to implement effectively. Here are some techniques that can be used in a supervised setting:
2.1 Techniques for Selecting Exemplars
2.1.1 K-Nearest Neighbor (KNN)
Run your examples through KNN and selects exemplars similar to test to boost performance
Effective but can be time and resource-intensive during prompt generation
2.1.2 Vote-K
Two-stage process for selecting similar exemplars:
Model proposes useful unlabeled candidate exemplars for annotation
Labeled pool is used for Few-Shot Prompting
Ensures diversity and representativeness of exemplars
2.1.3 Self-Generated In-Context Learning (SG-ICL)
Uses a generative AI to automatically generate exemplars
Better than zero-shot scenarios when training data is unavailable
Generated samples are not as effective as actual data
2.2 Prompt Mining
Process of discovering optimal "middle words" in prompts through large corpus analysis
Aims to find prompt formats that occur frequently in the corpus
Frequently occurring formats may lead to improved prompt performance
Example: Instead of using "Q: A:" format, finding a similar but more common format in the corpus
These techniques can help improve the effectiveness of few-shot prompting by optimizing exemplar selection and prompt format. The choice of technique may depend on the specific task, available resources, and the characteristics of the dataset and model being used.
3. Zero-Shot Prompting Techniques
Zero-Shot Prompting uses no exemplars, in contrast to Few-Shot Prompting. Here are several standalone zero-shot techniques:
3.1 Role Prompting (Persona Prompting)
Assigns a specific role to the AI in the prompt (e.g., "You are a travel writer")
Can improve outputs for open-ended tasks and sometimes improve accuracy on benchmarks
Example:
You are an experienced travel writer for a luxury lifestyle magazine. Describe the experience of visiting the {{city}} in {{country}}, focusing on the sensory details and exclusive experiences a high-end traveler might enjoy.3.2 Style Prompting
Specifies desired style, tone, or genre in the prompt
Similar effect can be achieved using role prompting
Examples:
Write a short sales pitch for a {{product}} in a persuasive, benefit-focused style. Emphasize how the product solves customer problems in a straightforward way.Compose a follow-up email to a potential client {{client_name}} after a sales call, using a friendly and conversational tone. The goal is to build rapport and schedule a product demo.Convert the following git commit message and code diff into a clear, concise changelog entry. Use a professional tone and focus on the user-facing changes and improvements. The entry should be understandable to non-technical users.3.3 Emotion Prompting
Incorporates phrases of psychological relevance to humans (e.g., "This is important to my career")
May lead to improved performance on benchmarks and open-ended text generation
3.4 System 2 Attention (S2A)
Asks the AI to rewrite the prompt, removing unrelated information
Passes the new prompt to the AI for a final response
Example:
System prompt:
Given the following text by a user, extract the part that is unbiased and not their opinion, so that using that text alone would be good context for providing an unbiased answer to the question portion of the text.
Please include the actual question or query that the user is asking. Separate this into two categories labeled with “Unbiased text context (includes all content except user’s bias):” and “Question/Query (does not include user bias/preference):”.
--
Quest: Text by User: [ORIGINAL INPUT PROMPT]https://arxiv.org/pdf/2311.11829
3.5 SimToM (Simulation Theory of Mind)
Deals with complicated questions involving multiple people or objects
Establishes the set of facts one person knows
Answers the question based only on those facts
Helps eliminate the effect of irrelevant information in the prompt
Single Prompt:
Your task is in two steps.
Step 1. output only the events that
{character_name} knows about.
Step 2. Imagine you are {character_name},
then answer a question based only on the
events {character_name} knows about.
Story: {story}
Question: {question}The following is a sequence of events about some characters, that takes place in multiple locations.
Your job is to output only the events that the specified character, {character}, knows about.
Here are a few rules:
1. A character knows about all events that they do.
2. If a character is in a certain room/location, that character knows about all other events that happens in the room. This includes other characters leaving or exiting the location, the locations of objects in that location, and whether somebody moves an object to another place. 3. If a character leaves a location, and is NOT in that location, they no longer know about any events that happen within that location. However, they can re-enter the location.
Story: {story}
What events does {character} know about?
Only output the events according to the
above rules, do not provide an
explanation.{perspective}
You are {name}.
Based on the above information, answer the following question:
{question}
Keep your answer concise, one sentence is
enough. You must choose one of the above
choices.Imagine you are {name}, and consider this story that has an unexpected event.
{story}
If the last sentence of the story says {name} notices, sees or realizes the unexpected event in this story, simply output the original story with nothing
changed.
However, if the sentence says you are not aware of the changes in this story, output only the events you know, i.e., the sentences before the unexpected event happens.
Output either the original story or the edited story, nothing else.
Format your answer as follows:
Sees/Notices/Realizes: (Yes/No)
Story:Answer the questions based on the context.
Keep your answer concise, few words are
enough, maximum one sentence. Answer as
’Answer:<option>)<answer>’.
{perspective}
You are {name}.
{question}
Choose the most straightforward answer.Task Instructions:
I will give you an excerpt. Your task involves three steps:
1. Identify the Sentence Describing the Unexpected Change:
Find the sentence that describes how the situation unexpectedly changed.
2. Determine the Main Character's Awareness:
Identify if the main character comes to know about, or notices, this change at the end.
3. Edit Based on Awareness:
- If the main character does not know about this change, edit the excerpt and output the part of the excerpt BEFORE the sentence that describes the change.
- If the main character does know about the change, do not edit the excerpt, and output the original story.
Examples:
Story:
Olumide, a skilled woodcarver in a Nigerian village, is preparing to carve a beautiful sculpture for the village chief. Olumide wants to use a sharp chisel to create intricate details on the sculpture. Olumide observes his set of chisels and sees one that appears to be sharp and in perfect condition. However, while Olumide is talking to a fellow artisan, a child from the village accidentally drops the chisel, causing it to become blunt and damaged. Olumide does not notice the damaged chisel on the ground.
Sentence: However, while Olumide is talking to a fellow artisan, a child from the village accidentally drops the chisel, causing it to become blunt and damaged.
Knows about or notices change: No
Edit:
Olumide, a skilled woodcarver in a Nigerian village, is preparing to carve a beautiful sculpture for the village chief. Olumide wants to use a sharp chisel to create intricate details on the sculpture. Olumide observes his set of chisels and sees one that appears to be sharp and in perfect condition.
Story:
{story}https://arxiv.org/pdf/2311.10227
3.6 Rephrase and Respond (RaR)
Instructs the AI to rephrase and expand the question before generating the final answer
Can be done in a single pass or as separate steps
Has shown improvements on multiple benchmarks

https://arxiv.org/pdf/2311.04205
3.7 Re-reading (RE2)
Adds the phrase "Read the question again:" to the prompt and repeats the question
Simple technique that has shown improvement in reasoning benchmarks, especially with complex questions
Example:
########### Task Instruction ##############
# You will write python program to solve math problems.
# You will only write code blocks.
# Please generate your code block in 'def solution()' function, and thus it can be executed by python interpreter. You don't need to call 'solution()' function because
# it will be called by the system.
# The concrete format of 'solution()' is as follows:
# def solution():
# """<question>"""
# <your code>
# result = <your result>
# return result
#########################################
# Q: {question}
# Read the question again: {question}
# Your defined "solution()" function with comments here.https://arxiv.org/pdf/2309.06275


3.8 Self-Ask
Prompts the AI to decide if follow-up questions are needed
If needed, the AI generates these questions
The AI answers the follow-up questions
Finally, the AI answers the original question
These zero-shot techniques can be used individually or in combination with other prompting methods to improve AI performance on various tasks without the need for task-specific examples.
Paper has both a zero-shot and the following four-shot example:
prompt = ['''Question: Who lived longer, Muhammad Ali or Alan Turing?
Are follow up questions needed here: Yes.
Follow up: How old was Muhammad Ali when he died?
Intermediate answer: Muhammad Ali was 74 years old when he died.
Follow up: How old was Alan Turing when he died?
Intermediate answer: Alan Turing was 41 years old when he died.
So the final answer is: Muhammad Ali
Question: When was the founder of craigslist born?
Are follow up questions needed here: Yes.
Follow up: Who was the founder of craigslist?
Intermediate answer: Craigslist was founded by Craig Newmark.
Follow up: When was Craig Newmark born?
Intermediate answer: Craig Newmark was born on December 6, 1952.
So the final answer is: December 6, 1952
Question: Who was the maternal grandfather of George Washington?
Are follow up questions needed here: Yes.
Follow up: Who was the mother of George Washington?
Intermediate answer: The mother of George Washington was Mary Ball Washington.
Follow up: Who was the father of Mary Ball Washington?
Intermediate answer: The father of Mary Ball Washington was Joseph Ball.
So the final answer is: Joseph Ball
Question: Are both the directors of Jaws and Casino Royale from the same country?
Are follow up questions needed here: Yes.
Follow up: Who is the director of Jaws?
Intermediate Answer: The director of Jaws is Steven Spielberg.
Follow up: Where is Steven Spielberg from?
Intermediate Answer: The United States.
Follow up: Who is the director of Casino Royale?
Intermediate Answer: The director of Casino Royale is Martin Campbell.
Follow up: Where is Martin Campbell from?
Intermediate Answer: New Zealand.
So the final answer is: No
Question: ''',
'''
Are follow up questions needed here:''', ]https://github.com/ofirpress/self-ask?tab=readme-ov-file
4. Thought Generation Techniques
Thought Generation encompasses techniques that prompt the AI to articulate its reasoning while solving a problem. These methods can significantly enhance performance in mathematics and reasoning tasks.
4.1 Chain-of-Thought (CoT) Prompting
Uses few-shot prompting to encourage the AI to express its thought process
Prompt includes an exemplar with a question, reasoning path, and correct answer
Example format:
Q: Jack has two baskets, each containing three balls. How many balls does Jack have in total?
A: One basket contains 3 balls, so two baskets contain 3 * 2 = 6 balls.
Q: {QUESTION}
A:4.2 Zero-Shot-CoT
Requires no exemplars
Appends a thought-inducing phrase to the prompt, such as:
"Let's think step by step."
"Let's work this out in a step by step way to be sure we have the right answer."
"First, let's think about this logically."
Task-agnostic and doesn't require exemplars
4.3 Step-Back Prompting
Modification of CoT
First asks a generic, high-level question about relevant concepts or facts
Then proceeds with reasoning
Has shown significant improvements on reasoning benchmarks

https://arxiv.org/pdf/2310.06117
4.4 Analogical Prompting
Similar to Self-Generated In-Context Learning (SG-ICL)
Automatically generates exemplars that include Chains of Thought
Demonstrated improvements in mathematical reasoning and code generation tasks

https://arxiv.org/pdf/2310.01714
4.5 Thread-of-Thought (ThoT) Prompting
Uses an improved thought inducer: "Walk me through this context in manageable parts step by step, summarizing and analyzing as we go."
Particularly effective in question-answering and retrieval settings with large, complex contexts

4.6 Tabular Chain-of-Thought (Tab-CoT)
Zero-Shot CoT prompt that makes the AI output reasoning as a markdown table
Tabular design improves the structure and reasoning of the output
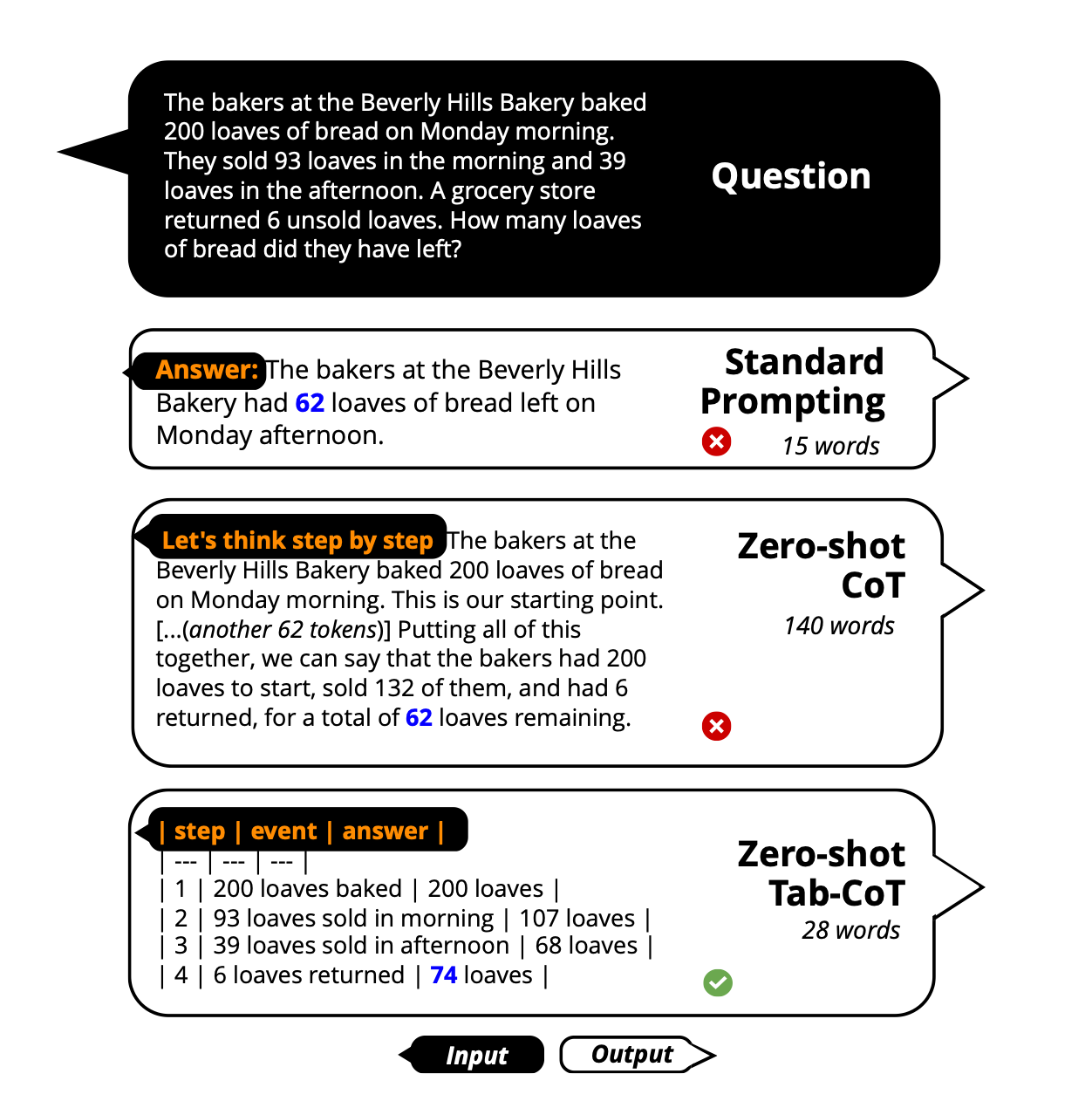

https://arxiv.org/pdf/2305.17812
These Thought Generation techniques aim to improve the AI's problem-solving capabilities by making its reasoning process more explicit and structured. They can be particularly useful for complex tasks that require step-by-step reasoning or analysis.
4.7 Few-Shot Chain-of-Thought (CoT) Techniques
Few-Shot CoT techniques present the AI with multiple exemplars that include chains-of-thought. This approach can significantly enhance performance and is sometimes referred to as Manual-CoT or Golden CoT.
4.7.1 Contrastive Chain-of-Thought
Shows the AI how not to reason
Has shown significant improvement in areas like Arithmetic Reasoning and Factual QA
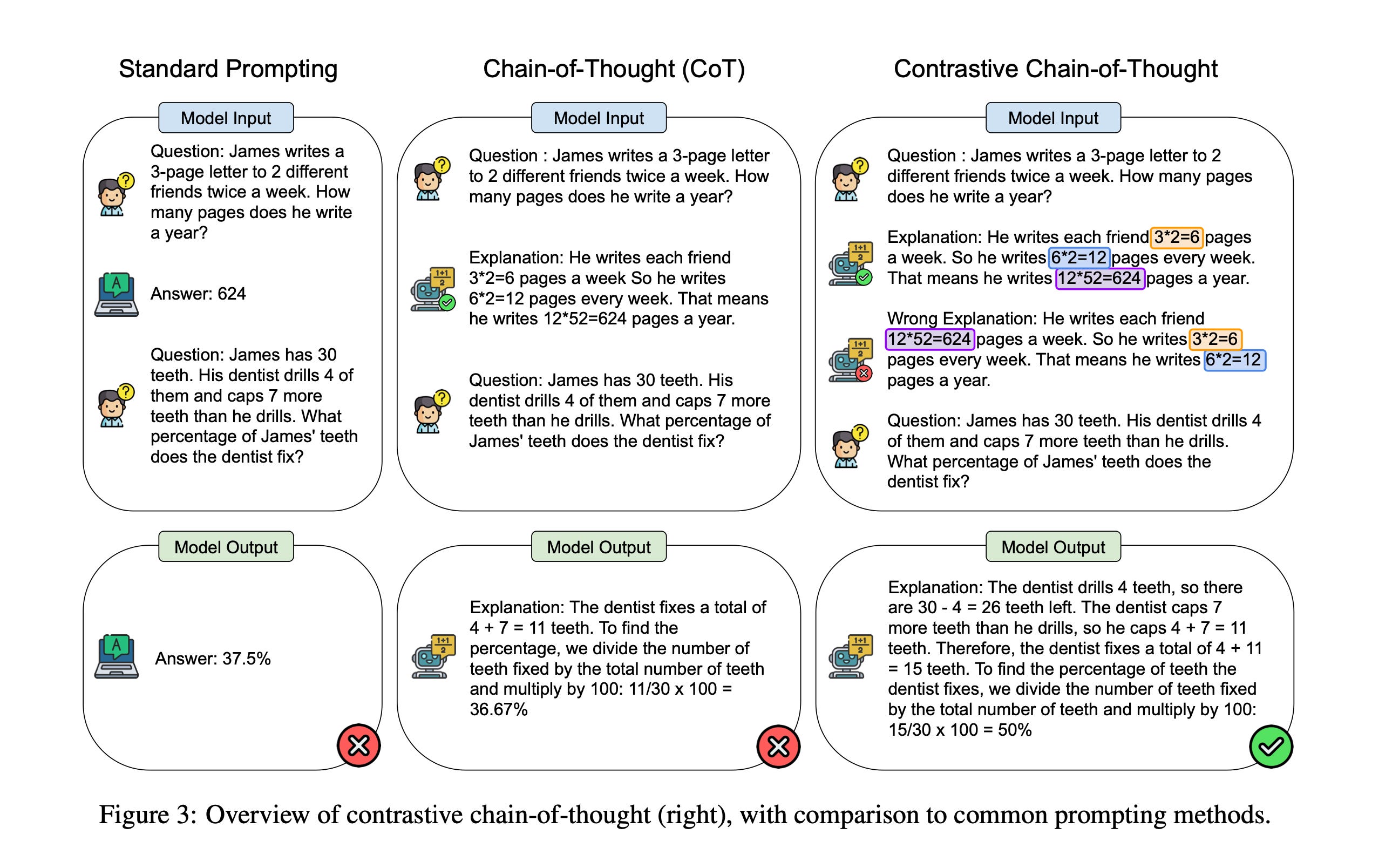
https://arxiv.org/pdf/2311.09277
4.7.2 Uncertainty-Routed CoT Prompting
Samples multiple CoT reasoning paths
Demonstrates improvement on both GPT-4 and Gemini Ultra models
Note: Didn’t read in full
https://storage.googleapis.com/deepmind-media/gemini/gemini_1_report.pdf
4.7.3 Complexity-based Prompting
Two major modifications to CoT:
Selects complex examples for annotation and inclusion in the prompt
During inference, samples multiple reasoning chains and uses a majority vote among chains exceeding a certain length threshold
Premise: Longer reasoning indicates higher answer quality
Has shown improvements on math reasoning datasets
Note: GPT-3 / Codex and tested
https://arxiv.org/pdf/2210.00720
4.7.4 Active Prompting
Starts with some training questions/exemplars
Asks the AI to solve them
Calculates uncertainty (disagreement in this case)
Asks human annotators to rewrite the exemplars with highest uncertainty
Note: another math-focused, but this could likely work well with reasoning q too.
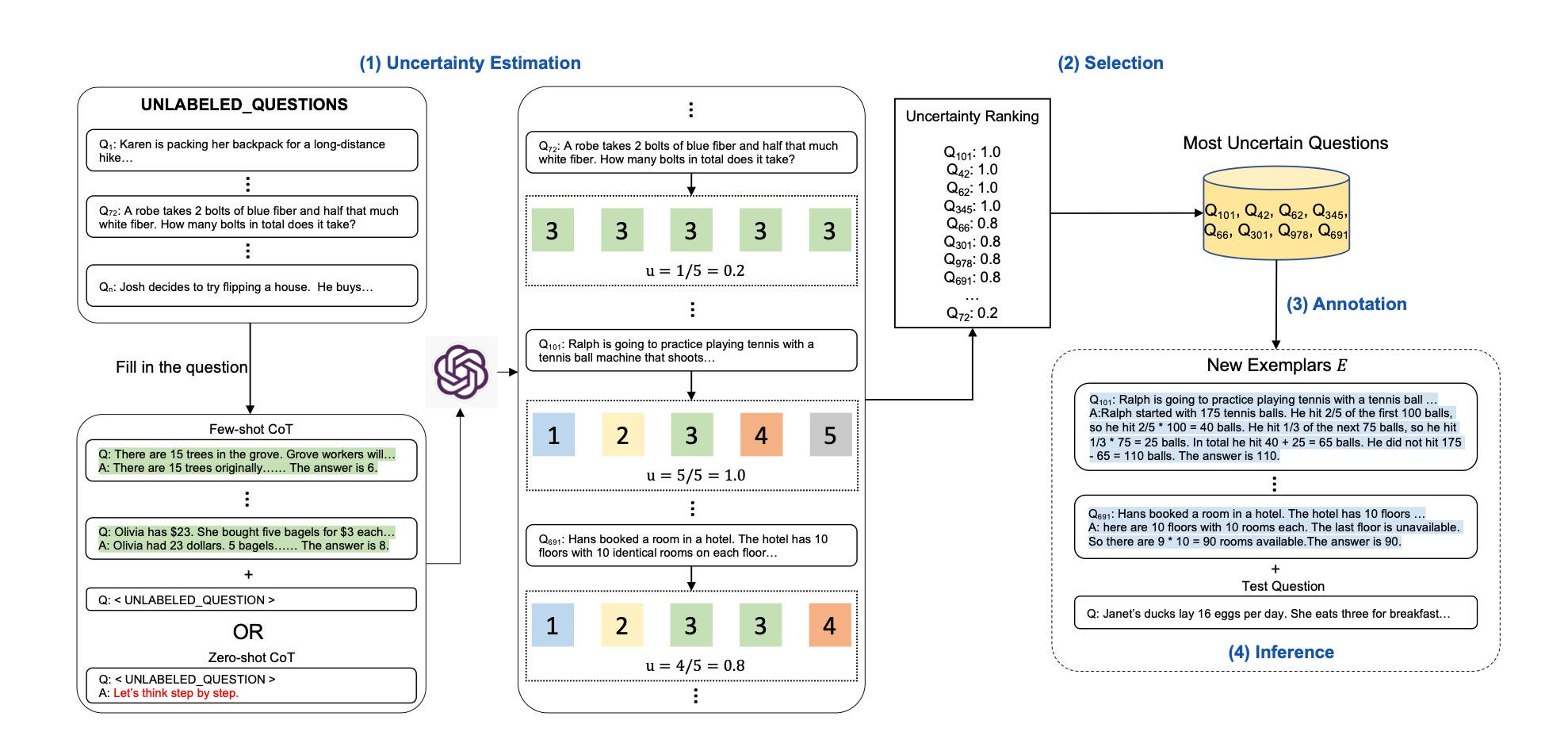
https://arxiv.org/pdf/2302.12246
4.7.5 Memory-of-Thought Prompting
Using unlabeled training exemplars to build Few-Shot CoT prompts at test time
Before test time: Performs inference on unlabeled training exemplars with CoT
At test time: Retrieves similar instances to the test sample
Improvements for Arithmetic, commonsense, and factual reasoning
Note: this one I didn’t understand the proposed architecture in practice
https://arxiv.org/pdf/2305.05181
4.7.6 Automatic Chain-of-Thought (Auto-CoT) Prompting
Uses Zero-Shot prompt to automatically generate chains of thought
Uses these generated chains to build a Few-Shot CoT prompt for a test sample
Note: GPT-3
https://arxiv.org/pdf/2210.03493
5. Decomposition Techniques
Decomposition techniques focus on breaking down complex problems into simpler sub-questions, which can significantly improve AI problem-solving abilities. While some of these techniques are similar to thought-inducing methods like Chain-of-Thought (CoT), they explicitly focus on problem breakdown.
5.1 Least-to-Most Prompting
Prompts the AI to break a problem into sub-problems without solving them
Solves sub-problems sequentially, appending responses to the prompt each time
Arrives at a final result

https://arxiv.org/pdf/2205.10625
5.2 Decomposed Prompting (DECOMP)
Uses Few-Shot prompting to teach the AI how to use certain functions (e.g., string splitting, internet searching)
AI breaks down the original problem into sub-problems and sends them to different functions
Functions are often implemented as separate AI calls
Has shown improved performance over Least-to-Most prompting on some tasks
Note: GPT3
https://arxiv.org/pdf/2205.10625
5.3 Plan-and-Solve Prompting
Uses an improved Zero-Shot CoT prompt: "Let's first understand the problem and devise a plan to solve it. Then, let's carry out the plan and solve the problem step by step"
Generates more robust reasoning processes than standard Zero-Shot-CoT on multiple reasoning datasets

https://arxiv.org/pdf/2305.04091
5.4 Tree-of-Thought (ToT)
Creates a tree-like search problem starting with an initial problem
Generates multiple possible steps in the form of thoughts (as from a CoT)
Evaluates the progress of each step towards solving the problem (through prompting)
Decides which steps to continue with and keeps creating more thoughts
Particularly effective for tasks that require search and planning
https://github.com/princeton-nlp/tree-of-thought-llm
(relevant prompts)
5.5 Recursion-of-Thought
Similar to regular CoT, but when it encounters a complicated problem in the reasoning chain, it sends this problem into another prompt/AI call
Inserts the answer from the sub-problem back into the original prompt
Can recursively solve complex problems, including those that might exceed the maximum context length
Has shown improvements on arithmetic and algorithmic tasks
5.6 Faithful Chain-of-Thought
Generates a CoT that includes both natural language and symbolic language (e.g., Python) reasoning
Uses different types of symbolic languages in a task-dependent fashion
Note: can’t think of a practical use for this, still cool nonetheless
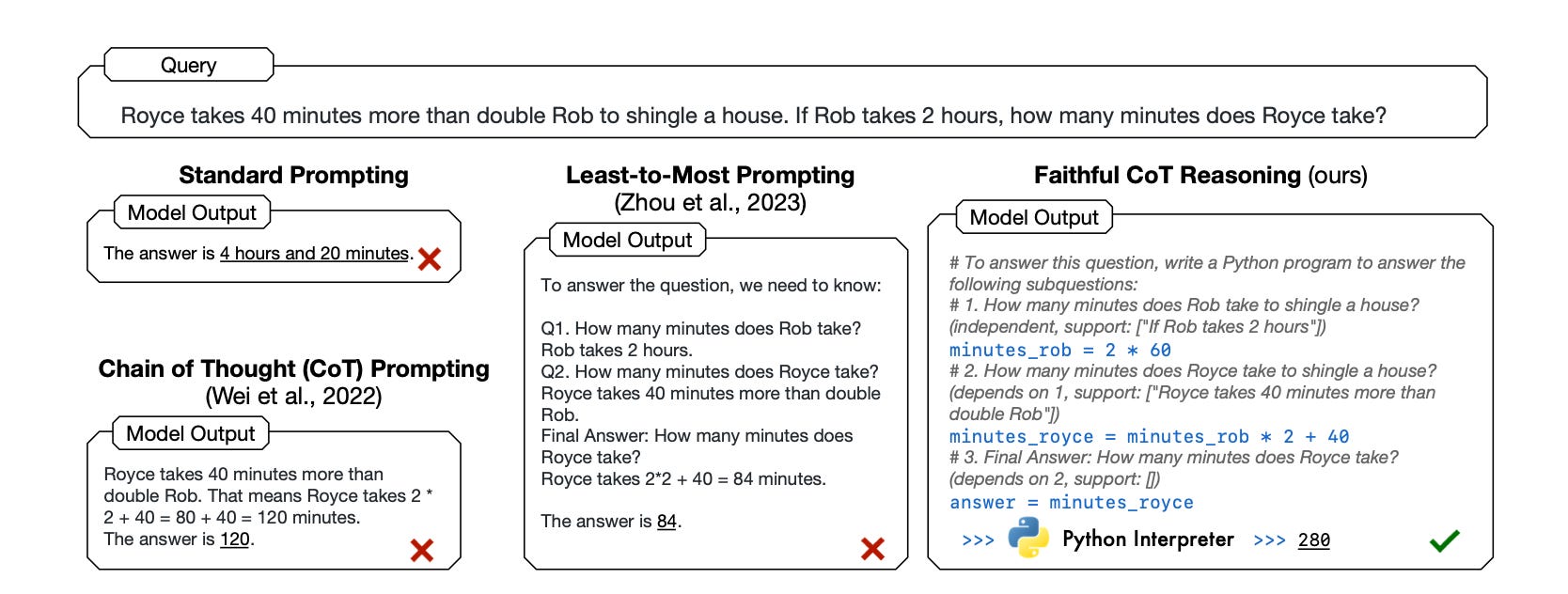
5.7 Skeleton-of-Thought
Prompts the AI to create a skeleton of the answer (sub-problems to be solved)
Sends these questions to an AI in parallel
Concatenates all the outputs to get a final response
Focuses on accelerating answer speed through parallelization

https://arxiv.org/pdf/2307.15337
6. Ensembling Techniques
Ensembling involves using multiple prompts to solve the same problem and then aggregating these responses into a final output. These techniques often improve accuracy and reduce output variance but increase cost.
6.1 Demonstration Ensembling (DENSE)
Creates multiple few-shot prompts, each with a distinct subset of exemplars from the training set
Aggregates outputs to generate a final response
6.2 Mixture of Reasoning Experts (MoRE)
Creates diverse reasoning experts using specialized prompts for different reasoning types
Selects the best answer based on an agreement score

https://arxiv.org/pdf/2305.14628
6.3 Max Mutual Information Method
Creates multiple prompt templates with varied styles and exemplars
Selects the optimal template that maximizes mutual information between the prompt and the AI's outputs
6.4 Self-Consistency
Samples multiple reasoning paths for a given input
Selects the most consistent output as the final response
Has shown improvements on arithmetic, commonsense, and symbolic reasoning tasks
6.5 Universal Self-Consistency
Similar to Self-Consistency, but uses a prompt template to select the majority answer
Helpful for free-form text generation and cases where the same answer may be output differently by different prompts
https://arxiv.org/pdf/2311.17311
6.6 Meta-Reasoning over Multiple CoTs
Generates multiple reasoning chains for a given problem
Inserts all chains into a single prompt template
Generates a final answer from the combined chains
https://arxiv.org/pdf/2304.13007
6.7 DiVeRSe
Creates multiple prompts for a given problem
Performs Self-Consistency for each, generating multiple reasoning paths
Scores reasoning paths based on each step
Selects a final response based on scores
6.8 Consistency-based Self-adaptive Prompting (COSP)
Runs Zero-Shot CoT with Self-Consistency on a set of examples
Selects a high agreement subset of outputs to be included in the final prompt as exemplars
Performs Self-Consistency again with this final prompt
6.9 Universal Self-Adaptive Prompting (USP)
Builds upon COSP to make it generalizable to all tasks
Uses unlabeled data to generate exemplars
Employs a more complicated scoring function to select exemplars
Does not use Self-Consistency
6.10 Prompt Paraphrasing
Transforms an original prompt by changing some wording while maintaining overall meaning
Acts as a data augmentation technique for generating prompts for an ensemble
Note: 2020, still makes sense though
7. Self-Criticism Techniques
Self-Criticism techniques involve having AI models evaluate and improve their own outputs. These methods can range from simple judgments to providing detailed feedback for improvement.
7.1 Self-Calibration
Prompts the AI to answer a question
Builds a new prompt including the question, the AI's answer, and an instruction asking whether the answer is correct
Useful for gauging confidence levels and deciding when to accept or revise the original answer
https://arxiv.org/pdf/2207.05221
7.2 Self-Refine
Gets an initial answer from the AI
Prompts the AI to provide feedback on its own answer
Prompts the AI to improve the answer based on the feedback
Repeats the process until a stopping condition is met
Has demonstrated improvement across reasoning, coding, and generation tasks
https://arxiv.org/pdf/2303.17651
7.3 Reversing Chain-of-Thought (RCoT)
Prompts the AI to reconstruct the problem based on its generated answer
Generates fine-grained comparisons between the original and reconstructed problems to check for inconsistencies
Converts inconsistencies to feedback for the AI to revise the generated answer
7.4 Self-Verification
Generates multiple candidate solutions with Chain-of-Thought (CoT)
Scores each solution by masking parts of the original question and asking the AI to predict them based on the rest of the question and the generated solution
Has shown improvement on eight reasoning datasets
7.5 Chain-of-Verification (COVE)
Uses the AI to generate an answer to a given question
Creates a list of related questions to help verify the correctness of the answer
Each verification question is answered by the AI
All information is given to the AI to produce the final revised answer
Improvements in various question-answering and text-generation tasks
7.6 Cumulative Reasoning
Generates several potential steps in answering the question
Has the AI evaluate these steps, deciding to accept or reject each
Checks whether it has arrived at the final answer
If not, repeats the process
Better output in logical inference tasks and mathematical problems
8. Evaluation Techniques
LLMs can be used as evaluators, extracting and reasoning about information to assess the quality of texts or other LLM outputs. This section covers key components of evaluation frameworks using LLMs.
8.1 Prompting Techniques for Evaluation
Evaluation prompts often benefit from standard text-based prompting techniques, including:
In-Context Learning: Provides examples of evaluations to guide the model.
Role-based Evaluation: Assigns specific roles to the LLM to generate diverse evaluations or create a multi-agent debate setting.
Chain-of-Thought: Improves evaluation performance by encouraging step-by-step reasoning.
Model-Generated Guidelines: Prompts the LLM to generate its own evaluation guidelines, reducing inconsistencies from ill-defined scoring criteria.
8.2 Output Formats
The format of the LLM's evaluation output can significantly affect performance:
Styling: Using XML or JSON formatting can improve judgment accuracy.
Linear Scale: Simple numerical scales (e.g., 1-5, 1-10, 0-1) for scoring.
Example:
Score the following story on a scale of 1-5 from well to poorly written: {INPUT}Binary Score: Yes/No or True/False responses for simple judgments.
Example:
Is the following story well written at a high-school level (yes/no)?: {INPUT}Likert Scale: Provides a more nuanced understanding of the scale.
Example:
Score the following story according to the following scale:
Poor Acceptable Good Very Good Incredible
{INPUT}8.3 Prompting Frameworks for Evaluation
These frameworks provide structured approaches to using LLMs for evaluation tasks:
8.3.1 LLM-EVAL
One of the simplest evaluation frameworks
Uses a single prompt containing:
A schema of variables to evaluate (e.g., grammar, relevance)
An instruction telling the model to output scores for each variable within a certain range
The content to evaluate
Notes: this works so well
https://arxiv.org/pdf/2305.13711
8.3.2 G-EVAL
Similar to LLM-EVAL, but includes AutoCoT (Automatic Chain-of-Thought) steps in the prompt itself
Process:
Generates evaluation steps according to the instructions
Inserts these steps into the final prompt
Weights answers according to token probabilities
Evaluate Coherence in the Summarization Task
You will be given one summary written for a news article.
Your task is to rate the summary on one metric.
Please make sure you read and understand these instructions carefully. Please keep this document open while reviewing, and refer to it as needed.
Evaluation Criteria:
Coherence (1-5) - the collective quality of all sentences. We align this dimension with the DUC quality question of structure and coherence whereby ”the summary should be well-structured and well-organized. The summary should not just be a heap of related informa- tion, but should build from sentence to sentence to a coherent body of information about a topic.”
Evaluation Steps:
1. Read the news article carefully and identify the main topic and key points.
2. Read the summary and compare it to the news article. Check if the summary covers the main topic and key points of the news article, and if it presents them in a clear and logical order.
3. Assign a score for coherence on a scale of 1 to 5, where 1 is the lowest and 5 is the highest based on the Evaluation Criteria.
Example: Source Text:
{{Document}}
Summary:
{{Summary}}
Evaluation Form (scores ONLY):
- Coherence:https://arxiv.org/pdf/2303.16634
8.3.3 ChatEval
Uses a multi-agent debate framework
Each agent has a separate role in the evaluation process
Allows for diverse perspectives and more nuanced evaluations
These frameworks demonstrate different approaches to structuring LLM-based evaluations, from simple single-prompt methods to more complex multi-agent systems. The choice of framework can depend on the complexity of the evaluation task and the desired level of detail and diversity in the assessment.
8.4 Other Evaluation Methodologies
In addition to explicit prompting for quality assessments, there are several other methodologies for LLM-based evaluation:
8.4.1 Implicit Scoring
While most approaches directly prompt the LLM to generate a quality assessment (explicit), some works also use implicit scoring where a quality score is derived using the model’s confidence in its prediction (Chen et al., 2023g) or the likelihood of generating the output (Fu et al., 2023a) or via the models’ explanation (e.g. count the number of errors as in Fernandes et al. (2023); Kocmi and Federmann (2023a)) or via evaluation on proxy tasks (factual inconsistency via entailment as in Luo et al. (2023))
TO-DO: Implicit has worked for most of my needs, I need to check these individual papers later
8.4.2 Batch Prompting
Evaluates multiple instances at once or the same instance under different criteria/roles. Improves compute and cost efficiency
8.4.3 Pairwise Evaluation vs Pointwise
Directly comparing the quality of two texts (Pairwise Evaluation) may lead to suboptimal results and that explicitly asking LLM to generate a score for individual summaries is the most effective and reliable method (Pointwise). The order of the inputs for pairwise comparisons can also heavily affect evaluation.
Note: relevant for summarization

https://arxiv.org/html/2406.12319v1
9. Prompting Issues: Security Concerns
https://arxiv.org/pdf/2311.16119
9.1 Types of Prompt Hacking
9.1.1 Prompt Injection
Overrides original developer instructions in the prompt with user input
Exploits the LLM's inability to distinguish between developer instructions and user input
9.1.2 Jailbreaking
Gets an LLM to perform unintended actions through prompting
Can be an architectural or training problem
9.2 Risks of Prompt Hacking
9.2.1 Data Privacy
Training Data Reconstruction: Extracting training data from LLMs
Prompt Leaking: Extracting the prompt template from an application
9.3 Hardening Measures
Some mitigation strategies:
9.3.1 Prompt-based Defenses
Include instructions in the prompt to avoid prompt injection
9.3.2 Guardrails
Rules and frameworks for guiding LLM outputs
Range from simple classification of user input to complex dialogue managers
9.3.3 Detectors
Tools designed to detect malicious inputs
Often built using fine-tuned models trained on malicious prompts
Generally more effective than prompt-based defenses
10. Prompting Issues: Alignment Concerns
10.1 Prompt Sensitivity
LLMs are highly sensitive to input prompts, with even subtle changes resulting in vastly different outputs.
10.1.1 Task Format
Different ways of phrasing the same task can significantly alter LLM performance.
Example: In sentiment analysis, asking to classify a review as "positive" or "negative" versus asking "Is this review positive?" (yes/no) can alter GPT-3's accuracy by up to 30% (Zhao et al., 2021b). (NOTE: I don’t think is relevant with GPT-4s anymore)
Even logically equivalent prompts, such as altering the order of choices in multiple-choice questions, can lead to significant performance degradation. (NOTE: same, don’t think it’s relevant anymore)
10.1.2 Prompt Drift
Occurs when the model behind an API changes over time, causing the same prompt to produce different results on the updated model.
10.2 Overconfidence and Calibration
LLMs often express overconfidence in their answers, which can lead to user overreliance on model outputs.
10.2.1 Verbalized Score
A simple calibration technique that generates a confidence score (e.g., "How confident are you from 1 to 10").
Efficacy is debated:
1 paper finds that LLMs are highly overconfident when verbalizing confidence scores, even when using self-consistency and chain-of-thought.
In contrast, another finds that simple prompts can achieve more accurate calibration than the model's output token probabilities.
Note: I have pretty good results with confidence scores on my use cases so far
10.2.2 Sycophancy
Refers to LLMs' tendency to agree with the user, even when contradicting their own initial output.
LLMs are easily swayed if the user's opinion is included in the prompt (e.g., "I really like/dislike this argument").
Questioning the LLM's original answer, strongly providing an assessment of correctness, or adding false assumptions can completely change the model output.
Sycophancy is heightened for larger and instruction-tuned models.
Solution: Avoid including personal opinions in prompts to prevent undue influence.
10.3 Biases, Stereotypes, and Culture
Efforts to ensure fairness and cultural sensitivity in LLM outputs include:
10.3.1 Vanilla Prompting
Simply instructing the LLM to be unbiased in the prompt.
Also referred to as moral self-correction.
10.3.2 Selecting Balanced Demonstrations
Using demonstrations optimized for fairness metrics.
Can help reduce biases in model outputs.
10.3.3 Cultural Awareness
Injecting cultural context into prompts to help LLMs with cultural adaptation.
Techniques include:
Asking the LLM to refine its own output.
Instructing the LLM to use culturally relevant words.
10.3.4 AttrPrompt
Designed to avoid biases in synthetic data generation .
Two-step process:
Asks the LLM to generate specific attributes important for diversity (e.g., location).
Prompts the LLM to generate synthetic data by varying each of these attributes.
10.4 Ambiguity
Addressing challenges posed by ambiguous questions that can be interpreted in multiple ways:
10.4.1 Ambiguous Demonstrations
Including examples with ambiguous label sets in prompts.
Can be automated with a retriever or done manually.
Shown to increase In-Context Learning performance.

https://arxiv.org/pdf/2309.07900
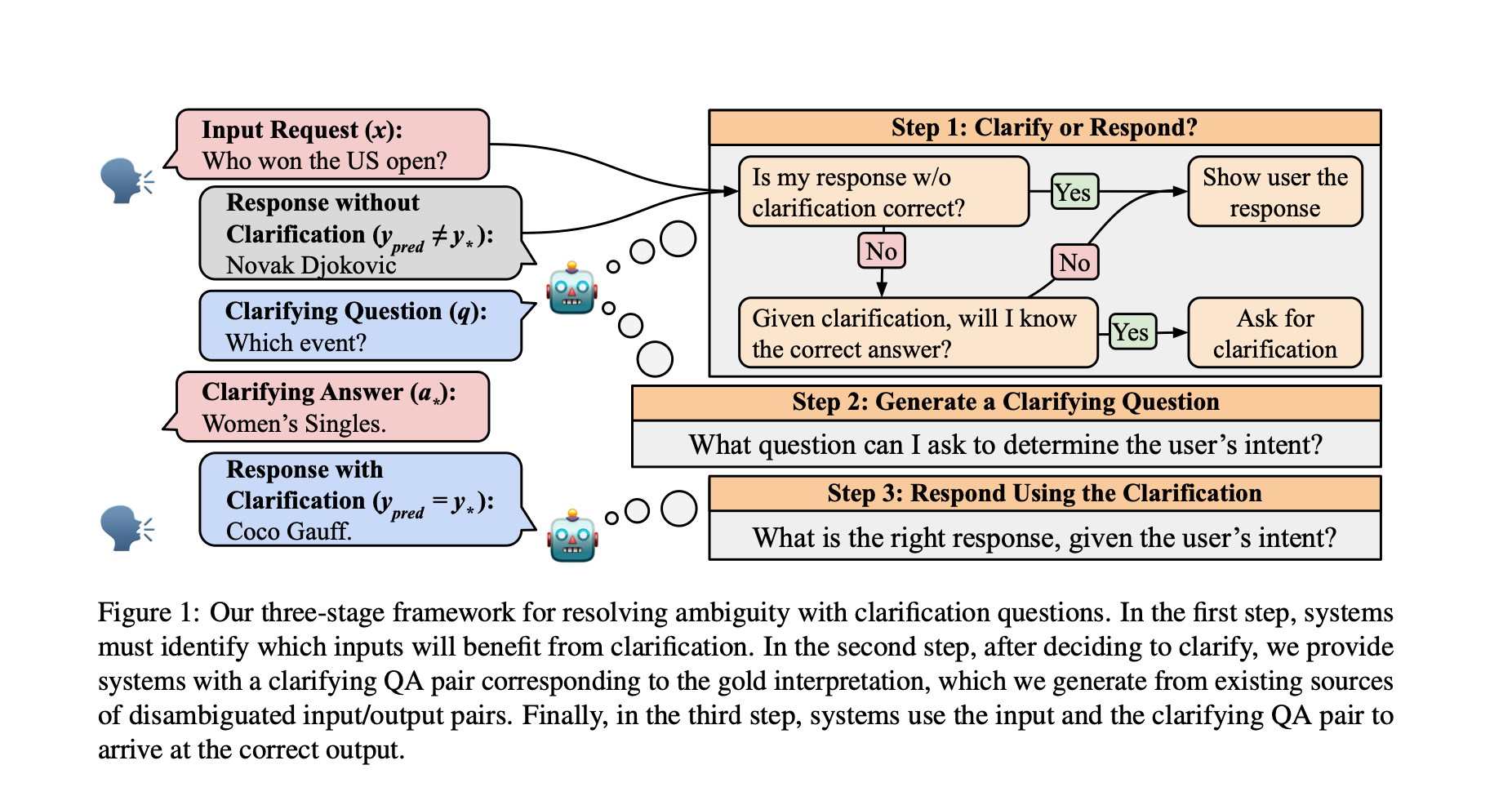
10.4.2 Question Clarification
Allows the LLM to identify ambiguous questions and generate clarifying questions.
Multi-step process:
Generate an initial answer.
Classify whether to generate clarification questions or return the initial answer.
Decide what clarification questions to generate.
Generate a final answer based on clarifications.
These alignment issues highlight the complexity of ensuring LLMs behave as intended across various contexts and user needs. Addressing these concerns is crucial for the responsible and effective deployment of LLM-based systems.
https://arxiv.org/pdf/2311.09469