
Week 10: Mostly LLM Evaluations
Machine learning + Evaluations

The first week of July has already passed. If you're new here, two months ago, I left my full-time job to focus on exploring LLMs. While I've learned a lot in just two months, June wasn't as productive as I'd hoped, with too much time spent on non-AI coding projects, leaving me with time for just theory and conferences. I'm aiming to correct this in July.
Traditional machine learning
When you move beyond simply calling APIs, you'll encounter the traditional ML stack and terminology. For instance, if you need to adjust your embeddings and choose a different model, you'll need a solid grasp of metrics like BPB, BPC, Perplexity, and so on. The same goes for evaluating production data.
I also prefer not to have components in a stack that I don't understand at a high level, even if I don't have to work with them directly (for example, if I'm an EM on the product side or a product manager).
For ML theory I’m currently half way through this course. It may be a few years old, but I appreciate how practical and real-world focused it is. If anyone has other suggestions, I'm very open to them.
I can't recall the exact source of this slide (I think it was from Hamel Hussain’s talk on AI Engineer conf this month) , but I believe it provides a reasonable overview - and my goal is to have at least a basic understanding of everything under the horizontal line.

Evaluations
Last week, I began studying evaluations more seriously for two reasons. First, I'm working on understanding the various stages of the development cycle. Second, I need to establish a better workflow for iterating on our AI bot at Canopy.
For theory around evals I really liked Chip’s third chapter of her WIP book. This post about Evaluations from Hamel Husain is also so good, and this one as well.
This is would be the ideal cycle for me:
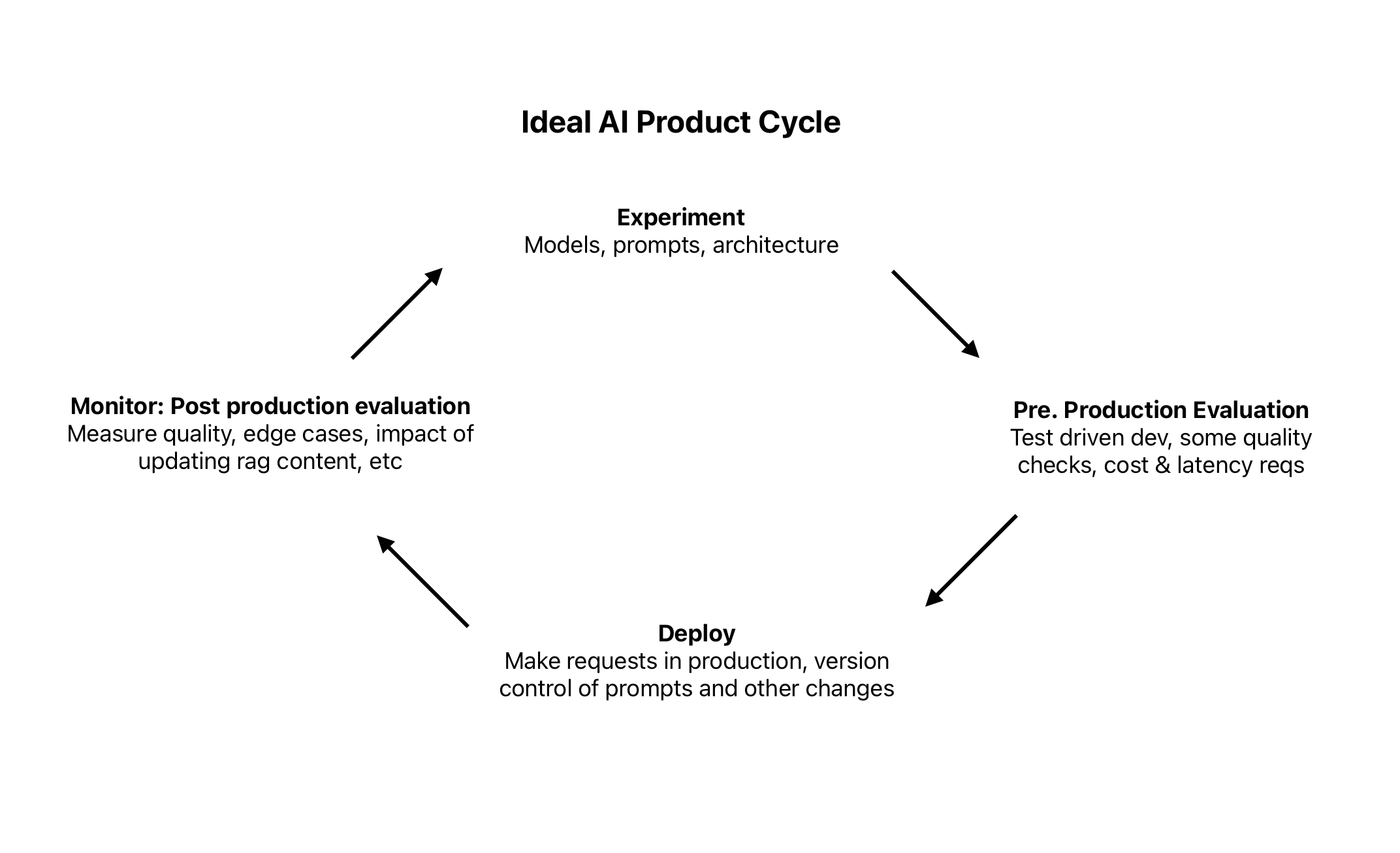
At Canopy, our tech stack is entirely Ruby, and our AI Assistant was built using direct API calls to OpenAI. While I did implement some observability, I still need a more robust way to monitor the quality of answers in production and a solid test suite that I can run when updating the model or modifying the prompts.
Ideally, I would have automated tests similar to regular test units that I can run whenever I'm iterating on prompts, models, or content format for the rag. Once things are deployed, I'd like to have comparable quality metrics for the production data, with alerts if quality drops below certain thresholds and proper visibility.
There are quite a few LLM-focused evaluation tools available, and many of them are really solid. I don't mean to dismiss their work, but for my specific context, here's my current assessment:
They do too much
Most tools attempt to offer solutions for all four stages of my diagram, but these companies are often small, seed-level teams building in a rapidly evolving space. Many of these products feel either half-baked or are still trying to figure out their business model. I'd prefer a tool that focuses solely on the two evaluation parts (dev & production) and doesn't try to handle the prototyping and deployment aspects.
Their business models are still unclear
Many tools are in the typical early-stage B2B mode, lacking a product-led path and aiming to lock users into annual contracts with case-by-case pricing. I understand this is important in a new market with early-stage products, but I'd love to see more product-led options (especially for Canopy's context, a small team where the bot isn't their core feature yet).
Vendor lock in / dependency risk
To enable tracing, many tools heavily wrap around API clients for services like OpenAI, and some don't even offer public API versions. Tools that offer "solutions" for the deployment part often proxy calls under their own API, so instead of calling OpenAI directly, you call their API. This introduces a third-party proxy as a potential failure point, in addition to OpenAI/Anthropic/etc., and it's built by an understaffed seed company.
Pretty much no solutions for non-Python/JavaScript stacks
Most niceties for automatic logging/tracing and basic metrics like latency come from their SDK, which are often limited to Python/JS. While understandable given the early stage, most tools also don't offer a public API. For more elaborate setups, a reasonable workflow could be to follow the traditional ML path of using Python for the stack and wrapping it as an API for other languages to call, instead of relying on a proxy maintained by a tiny company in a crowded space. It's a bit of a bummer because for AI products that only need LLMs, it's an overcomplication in the stack. You'll definitely need query augmentation, retries, rate-limiting controls, and other things a product-level software already handles, and now you'll need to duplicate that in the Python stack too. It's one thing when you're making an API around a model you control, but it's another when you're making an API around another API.
If you're already using a Python or JS stack, you have fewer things to worry about. However, for Canopy (Ruby stack), the situation is a bit different. I think I'll go with the following approach:
First: Find a tool that has a public API support for sending run data for production, build a small Ruby client for that, and do production level monitoring only (similar to how’d use a service like Sentry). Ignore all the other 3 stages of the Experiment and Deploy part of these tools.
Second:
Have a good unit test coverage for the direct calls to OpenAI with VCR and reimplement some of the basic eval metrics that relevant to my context like Answer Relevance, Context Recall, or Context Relevancy.
Or use something like Promptfoo, Ragas or GuardRails for the local unit tests.
I haven't decided which product to use yet, but reading through their documentation, examining the code of their SDKs, and exploring their offerings has been a good learning process already.
In no particular order, here's the current list of evaluation products/projects that I'm aware of (although I haven't had a chance to thoroughly check all of them yet):
https://mlflow.org
https://www.vellum.ai/
https://athina.ai
https://www.patronus.ai
https://wandb.ai/site/weave
https://autochain.forethought.ai/
https://ragas.io/
https://github.com/agenta-ai/agenta
https://klu.ai/
https://www.braintrustdata.com/
https://humanloop.com/
https://www.parea.ai/
https://docs.llamaindex.ai/en/stable/understanding/evaluating/evaluating/
https://www.langchain.com/langsmith
https://github.com/langfuse/langfuse
https://www.rungalileo.io/
https://www.guardrailsai.com/
https://deepchecks.com
https://arize.com
https://github.com/UKGovernmentBEIS/inspect_ai
If you're using a tool that you really like or if you have any feedback or a different perspective on the market, I'd love to hear your thoughts.